Foundation models have passed a tipping point and they are cropping up everywhere, in a huge variety of use cases. We can transcribe images, translate text, do object detection, and generate anything that our hearts desire. The simplest approach to solving a problem with machine learning now almost invariably begins with “send it to Claude, OpenAI, or both and see what happens” before digging into specific model implementation details.
Many natural language processing (NLP) tasks have been “solved” with this, at least in a very first pass of the data. Do you want to extract topics from a text? Do you want to summarize it? Do you want to judge whether it’s offensive or not? Send it to an LLM and log the output. Maybe later you use the output to train something specialized, but that first pass is very effective for standing up a proof of concept.
This information extraction aspect is a very powerful use of LLMs. Unstructured data within text is all around us, and bringing sense to it is the subject of thousands of papers and magnitudes more research and engineering hours. Features like “structured output”, where you can extract information in a data schema that you specify in advance, are even more powerful, providing reasonable guarantees on what you can expect from the output of an LLM rather than raw string information.
Tools like this open the door for extracting detailed information from unstructured data, bringing new [human-legible] order to the field. In this post, we explore using LLMs to extract ontologies for the purpose of automatically creating knowledge graphs.
Ontologies
An ontology is a collection of all the concepts and relationships between those concepts within a given data domain. An ontology is a blueprint, created with the intent of finding elements within the data that match that blueprint. When you know “what there is” and how those elements relate to each other, you are able to draw stronger conclusions and reason about those elements. This is the purpose of defining an ontology. We have developed a variety of specifications and implementations for building such blueprints, such as the Web Ontology Language (OWL).
A true ontology is often designed and implemented to enable reasoning, with built-in propositional logic and other strong features for bringing order to world. In our context, we are primarily concerned with the generation of a knowledge graph. We want to extract specific entities and relations from our data domain, and use that knowledge graph for various ends. Entities and Relations in an Ontology are a schema that we use to discover individual instances of those objects. For example, for a given ontology we might have an Author entity, a Book entity, and an authored Relation.
An ontology on something like “Horror by Arthur Machen” might have a setup akin to:
entities:
- name: Author
description: A writer of books, poetry, short stories, or other content.
Their writing can be short form or long form.
properties:
- name: name
type: str
required: true
- name: Book
description: A written or bound work of a number of pages on a given topic.
properties:
- name: title
type: str
required: true
- name: page_count
type: int
required: false
- name: subject
type: list[str]
required: false
- name: Character
description: Character within a work of fiction. A character is like a
person, but only within the context of a book.
properties:
- name: name
type: str
required: true
- name: occupation
type: str
required: false
relations:
- name: authored
description: An author writes or authors a book.
source_type: Author
target_type: Book
properties: []
- names: contains_character
description: Membership of a character or "player" within a book.
source_type: Book
target_type: Character
properties: []
- names: friends_with
description: Congenial relationship between two characters denoting
friendship.
source_type: Character
target_type: Character
properties: []
Then, a particular realization of this ontology on the domain might be:
EntityInstance(
id=0,
type="Author",
properties={
"name": "Arthur Machen"
}
)
EntityInstance(
id=1,
type="Book",
properties={
"title": "The Great God Pan",
"subject": ["magic", "occult"]
}
)
EntityInstance(
id=2,
type="Character",
properties={
"name": "Clarke"
}
)
EntityInstance(
id=3
type="Character",
properties={
"name": "Dr. Raymond",
"occupation": "scientist",
}
)
RelationInstance(
id=0,
type="authored",
source_id=0,
target_id=1,
properties={}
)
RelationInstance(
id=1,
type="friends_with",
source_id=2,
target_id=3,
properties={}
)
RelationInstance(
id=2,
type="contains_character",
source_id=1,
target_id=2,
properties={}
)
RelationInstance(
id=3,
type="contains_character",
source_id=1,
target_id=3,
properties={}
)
This realization of an ontology is a knowledge graph. The entity instances are nodes in the graph, and the relation instances are the edges between those nodes. You could go a step further here and include the raw texts themselves, connecting them to these more conceptual blobs, and you are fully connected. The ontology is the blueprint, the knowledge graph is the structure.
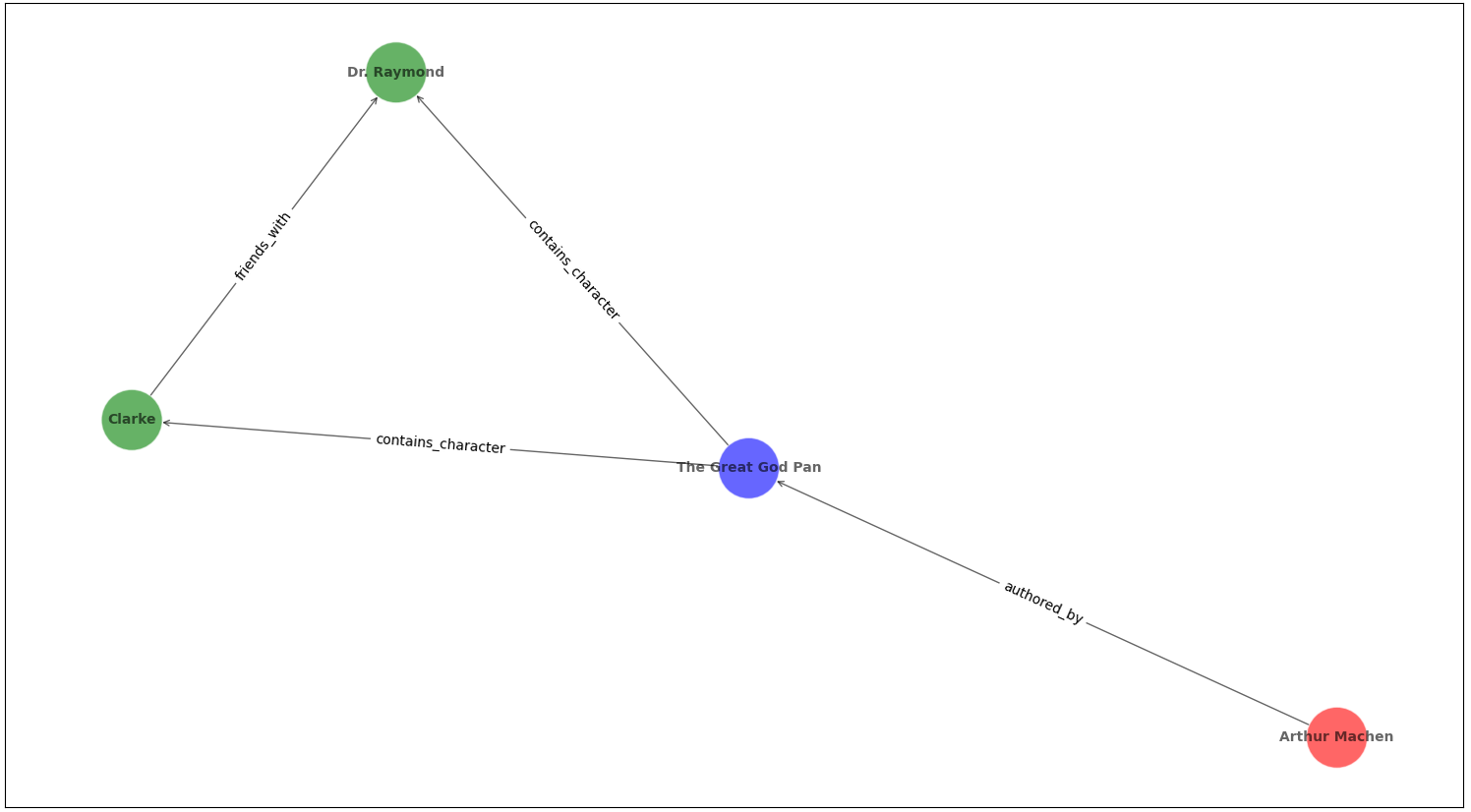
Knowing “what there is” gives us a stronger view of how those things are related to each other. If we have raw text embeddings for a variety of fragments of text, and one text fragment mentions the “Clarke” entity instance, we know that it should be “closer” to any fragments that contain “Dr. Raymond”. If we add additional works by Arthur Machen, we can build even richer relationships. Here’s a quick extension to our ontology:
entities:
- name: ShortStory
description: A short story, either in a collection or standalone.
properties:
- name: name
type: str
required: true
- name: Genre
description: Genre of a work of fiction.
properties:
- name: name
type: str
required: true
relations:
- name: contains_story
description: Relationship denoting that a larger work encompasses a smaller
work.
source_type: Book
target_type: ShortStory
- name: is_genre
description: Denotes membership of a work of fiction in a genre.
source_type: Book
target_type: Genre
And, without even realizing all kinds of entities and relations, we get more structure captured in the graph.
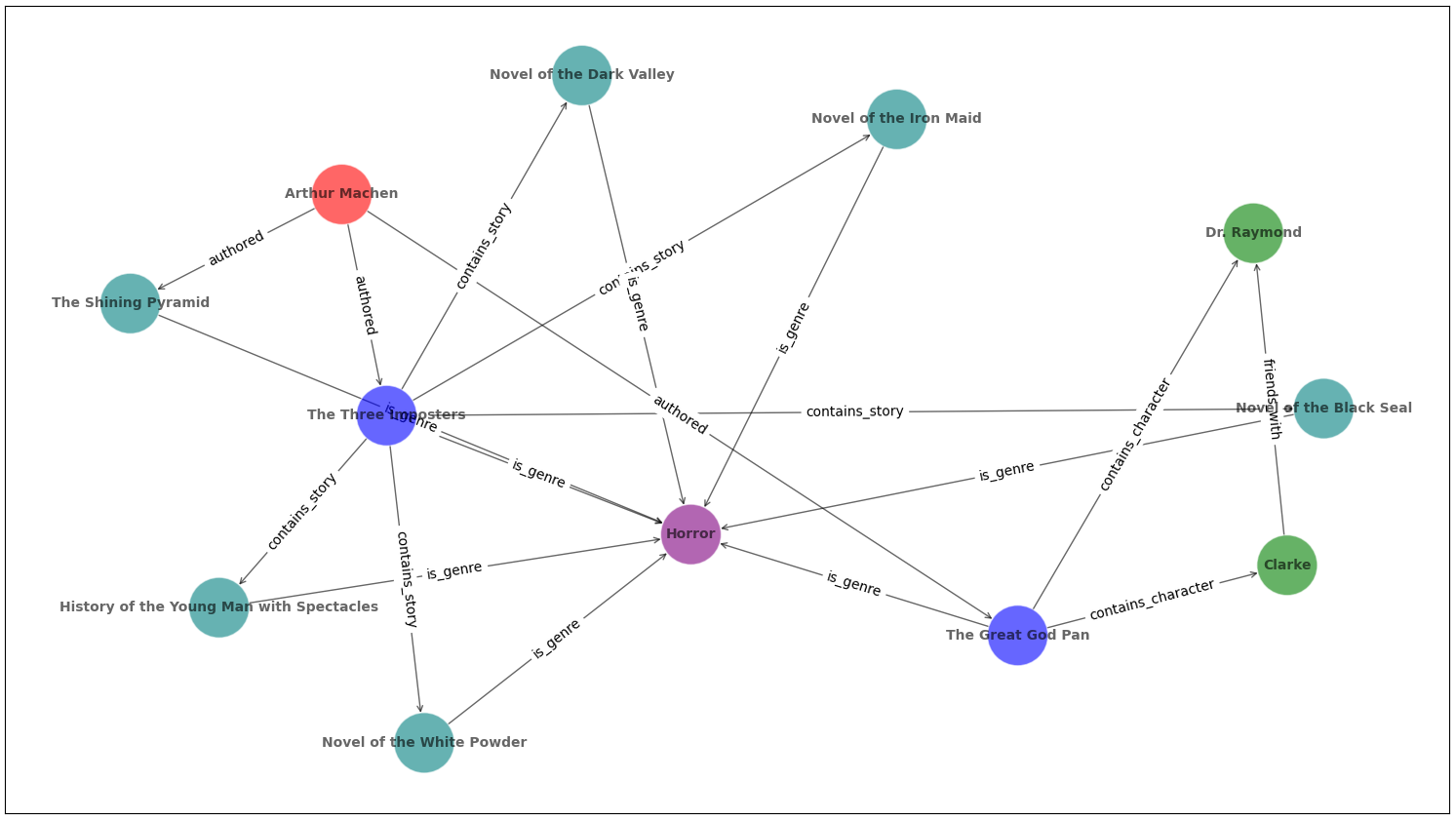
If we were to add more authors beyond the one, the complexity would increase significantly. This graphical structure can be used to improve our relationships between text in our target domain, enriching the accompanying embeddings.
Automated Extraction
So far, we’ve discussed a manually created ontology, but these become more useful when a machine can construct them for you.
We’ve developed a wide variety of tools historically for extracting ontologies from data, but if there’s one thing that large language models are good for, it’s reading text. For our purposes, we’ll use an LLM and structured outputs to extract our schema from a collection of works by early horror authors. If we allow the schema to follow a similar shape to the above examples and run an extraction with an LLM on:
- The Great God Pan, by Arthur Machen
- The Novel of the Black Seal, by Arthur Machen
- The Novel of the White Powder, by Arthur Machen
- The Lurking Fear, by H.P. Lovecraft
- The Horror at Red Hook, by H.P. Lovecraft
- The Turn of the Screw, by Henry James
from Project Gutenberg using GPT-5, we get the following:
horror_ontology.yaml
entities:
- name: Person
description: 'A human individual mentioned in the text (real or fictional); authors,
narrators, witnesses, suspects, victims, investigators, household members.'
properties:
- name: name
type: str
required: false
- name: role
type: str
required: false
- name: occupation
type: str
required: false
- name: age
type: int
required: false
- name: description
type: str
required: false
- name: aliases
type: list[str]
required: false
- name: Location
description: A geographic place, district, neighborhood, site, or general setting
referenced in the narrative.
properties:
- name: name
type: str
required: false
- name: type
type: str
required: false
- name: description
type: str
required: false
- name: Building
description: A constructed structure or dwelling (house, mansion, church, hall,
cellar) distinct from a broader Location.
properties:
- name: name
type: str
required: false
- name: function
type: str
required: false
- name: condition
type: str
required: false
- name: built_year
type: int
required: false
- name: Room
description: A specific interior space within a Building (study, nursery, tower
chamber, cellar).
properties:
- name: name
type: str
required: false
- name: function
type: str
required: false
- name: condition
type: str
required: false
- name: Artifact
description: A tangible object or item of material culture (seal, ring, weapon,
painting, furniture, specimen).
properties:
- name: name
type: str
required: false
- name: material
type: str
required: false
- name: description
type: str
required: false
- name: inscriptions_count
type: int
required: false
- name: Document
description: A written or printed item (manuscript, letter, report, book, packet)
referenced in the text.
properties:
- name: title
type: str
required: false
- name: type
type: str
required: false
- name: date
type: str
required: false
- name: summary
type: str
required: false
- name: Event
description: A temporally bounded occurrence or incident (discovery, crime, experiment,
meeting, voyage, storm).
properties:
- name: name
type: str
required: false
- name: date
type: str
required: false
- name: description
type: str
required: false
- name: event_type
type: str
required: false
- name: Organization
description: A formal or informal collective or institution (police, church, gang,
newspaper, cult organization).
properties:
- name: name
type: str
required: false
- name: type
type: str
required: false
- name: description
type: str
required: false
- name: Group
description: A collective of people acting together in the narrative (reporters,
squatters, followers).
properties:
- name: name
type: str
required: false
- name: description
type: str
required: false
- name: sizeEstimate
type: int
required: false
- name: Vessel
description: A seafaring craft, boat, or other conveyance used or mentioned in the
text.
properties:
- name: name
type: str
required: false
- name: type
type: str
required: false
- name: description
type: str
required: false
- name: Language
description: A named tongue, script, dialect or linguistic form referenced in connection
with inscriptions or speech.
properties:
- name: name
type: str
required: false
- name: description
type: str
required: false
- name: phonetic_notes
type: str
required: false
- name: Inscription
description: Textual marks carved, written, or painted on objects or natural features
(seals, rock inscriptions, mottos).
properties:
- name: content
type: str
required: false
- name: script
type: str
required: false
- name: character_count
type: int
required: false
- name: SupernaturalEntity
description: "Non\u2011natural or uncanny beings or phenomena (apparitions, deities,\
\ occult forces, transformations)."
properties:
- name: name
type: str
required: false
- name: description
type: str
required: false
- name: manifestations
type: list[str]
required: false
- name: Creature
description: "A non\u2011human organic or monstrous entity (animal, subterranean\
\ creature, beast) encountered in the narrative."
properties:
- name: name
type: str
required: false
- name: physical_description
type: str
required: false
- name: behavior
type: str
required: false
- name: Family
description: A kinship group, clan or lineage referenced in the narrative (family
ownership, descent).
properties:
- name: name
type: str
required: false
- name: description
type: str
required: false
- name: Substance
description: A material, chemical, or medicinal preparation (white powder, phial
contents, Vinum Sabbati).
properties:
- name: name
type: str
required: false
- name: physicalForm
type: str
required: false
- name: description
type: str
required: false
- name: MedicalCondition
description: A described physical or mental health state (fits, fever, hysteria,
convulsions).
properties:
- name: name
type: str
required: false
- name: symptoms
type: list[str]
required: false
- name: severity
type: str
required: false
- name: Experiment
description: A deliberate procedure, medical/occult operation, or scientific action
carried out to produce an outcome.
properties:
- name: name
type: str
required: false
- name: method
type: str
required: false
- name: description
type: str
required: false
relations:
- name: person_resides_in
description: A person lives in, is resident at, or is associated with a Location.
source_type: Person
target_type: Location
properties: []
- name: person_associated_with_person
description: A general social/professional relation between two people (friend,
guardian, employer, acquaintance).
source_type: Person
target_type: Person
properties: []
- name: person_employs
description: One person hires, supervises, or employs another person.
source_type: Person
target_type: Person
properties: []
- name: person_member_of_family
description: Associates a Person with the Family or clan they belong to.
source_type: Person
target_type: Family
properties: []
- name: family_owns_building
description: Indicates a Family owning, inhabiting, or associated with a Building.
source_type: Family
target_type: Building
properties: []
- name: person_member_of_organization
description: A Person belongs to or is affiliated with an Organization.
source_type: Person
target_type: Organization
properties: []
- name: person_member_of_group
description: A Person belongs to or is part of a Group.
source_type: Person
target_type: Group
properties: []
- name: organization_operates_in
description: An Organization operates, patrols, or is active within a Location.
source_type: Organization
target_type: Location
properties: []
- name: group_operates_in
description: A Group is active or present in a Location.
source_type: Group
target_type: Location
properties: []
- name: authored
description: A Person authored or wrote a Document.
source_type: Person
target_type: Document
properties: []
- name: document_mentions_person
description: A Document references, names, or discusses a Person.
source_type: Document
target_type: Person
properties: []
- name: document_references_artifact
description: A Document refers to, records, or describes an Artifact.
source_type: Document
target_type: Artifact
properties: []
- name: document_describes_event
description: A Document records or recounts an Event.
source_type: Document
target_type: Event
properties: []
- name: document_reports_supernatural
description: A Document records, describes, or reports a SupernaturalEntity or phenomenon.
source_type: Document
target_type: SupernaturalEntity
properties: []
- name: artifact_located_in_location
description: An Artifact is found at, originates from, or is kept in a Location.
source_type: Artifact
target_type: Location
properties: []
- name: artifact_in_building
description: An Artifact is located in or kept within a Building.
source_type: Artifact
target_type: Building
properties: []
- name: artifact_in_room
description: An Artifact is located in a specific Room.
source_type: Artifact
target_type: Room
properties: []
- name: artifact_has_inscription
description: An Artifact bears or displays an Inscription.
source_type: Artifact
target_type: Inscription
properties: []
- name: inscription_in_language
description: An Inscription is rendered in or associated with a Language or script.
source_type: Inscription
target_type: Language
properties: []
- name: room_part_of_building
description: A Room is a constituent part of a Building.
source_type: Room
target_type: Building
properties: []
- name: building_located_in
description: A Building is situated in or associated with a Location.
source_type: Building
target_type: Location
properties: []
- name: event_occurs_at
description: An Event takes place at or is tied to a Location.
source_type: Event
target_type: Location
properties:
- name: date
type: str
required: false
- name: event_involves_person
description: An Event involves, affects, or concerns one or more Persons (participants,
victims, witnesses).
source_type: Event
target_type: Person
properties: []
- name: event_involves_artifact
description: An Event involves or uses an Artifact (weapon, object of ritual, evidence).
source_type: Event
target_type: Artifact
properties: []
- name: person_participates_in_event
description: A Person is a participant, witness, or subject in an Event.
source_type: Person
target_type: Event
properties: []
- name: person_owns_artifact
description: A Person owns, possesses, or has custody of an Artifact.
source_type: Person
target_type: Artifact
properties: []
- name: person_possesses_document
description: A Person holds, controls, or is custodian of a Document.
source_type: Person
target_type: Document
properties: []
- name: person_aboards_vessel
description: A Person travels on, is aboard, or is found on a Vessel.
source_type: Person
target_type: Vessel
properties: []
- name: vessel_moored_at
description: A Vessel is moored, anchored, or located at a Location or Body of Water
(represented as Location).
source_type: Vessel
target_type: Location
properties: []
- name: vessel_involved_in_event
description: A Vessel is involved in or central to an Event (boarding, voyage, smuggling).
source_type: Vessel
target_type: Event
properties: []
- name: person_perceives_supernatural
description: A Person perceives, witnesses, or reports a SupernaturalEntity or phenomenon.
source_type: Person
target_type: SupernaturalEntity
properties: []
- name: supernatural_haunts_location
description: A SupernaturalEntity is associated with, appears in, or haunts a Location
or Building.
source_type: SupernaturalEntity
target_type: Location
properties: []
- name: supernatural_targets_person
description: A SupernaturalEntity is directed at, manifests to, or affects a particular
Person.
source_type: SupernaturalEntity
target_type: Person
properties: []
- name: creature_attacks_person
description: A Creature harms, attacks, or kills a Person.
source_type: Creature
target_type: Person
properties: []
- name: creature_inhabits_location
description: A Creature inhabits, dwells in, or is found at a Location.
source_type: Creature
target_type: Location
properties: []
- name: person_member_of_family
description: Associates a Person with a Family or lineage (kinship).
source_type: Person
target_type: Family
properties: []
- name: person_takes_substance
description: A Person ingests, applies, or is administered a Substance (drug, powder,
potion).
source_type: Person
target_type: Substance
properties: []
- name: person_has_medical_condition
description: A Person suffers from or is described as having a MedicalCondition.
source_type: Person
target_type: MedicalCondition
properties: []
- name: substance_affects_condition
description: A Substance has an effect on, causes, or treats a MedicalCondition.
source_type: Substance
target_type: MedicalCondition
properties: []
- name: conducts_experiment
description: A Person conducts, directs, or carries out an Experiment.
source_type: Person
target_type: Experiment
properties: []
- name: person_subject_of_experiment
description: A Person is the subject or recipient of an Experiment.
source_type: Person
target_type: Experiment
properties: []
- name: experiment_occurs_at
description: An Experiment is performed at a Location.
source_type: Experiment
target_type: Location
properties: []
- name: experiment_results_in
description: An Experiment produces or leads to a MedicalCondition or outcome.
source_type: Experiment
target_type: MedicalCondition
properties: []
This is structured output from the LLM. The general process is:
- Chunk each text into groups of
max_tokens, in this case8192. - Generate
Entitiesfor the chunk. - Generate
Relationsgiven the chunk and the text. - Consolidate all
Ontology(Entities, Relations)for each chunk into a finalOntology.
Key observations here are that:
- the model does not generate any properties that are required, every property is optional.
- the relations generated are fairly split. It might be better to try to define them slightly more generally, e.g.
occurs_atinstead ofexperiment_occurs_at.
I suspect that these issues could be alleviated with more in-depth prompting, as this was generated with a first draft of everything.
We can then use this ontology to find specific instances of the defined objects that appear in the text and create a knowledge graph. This knowledge graph is created using the above ontology on the same base texts.
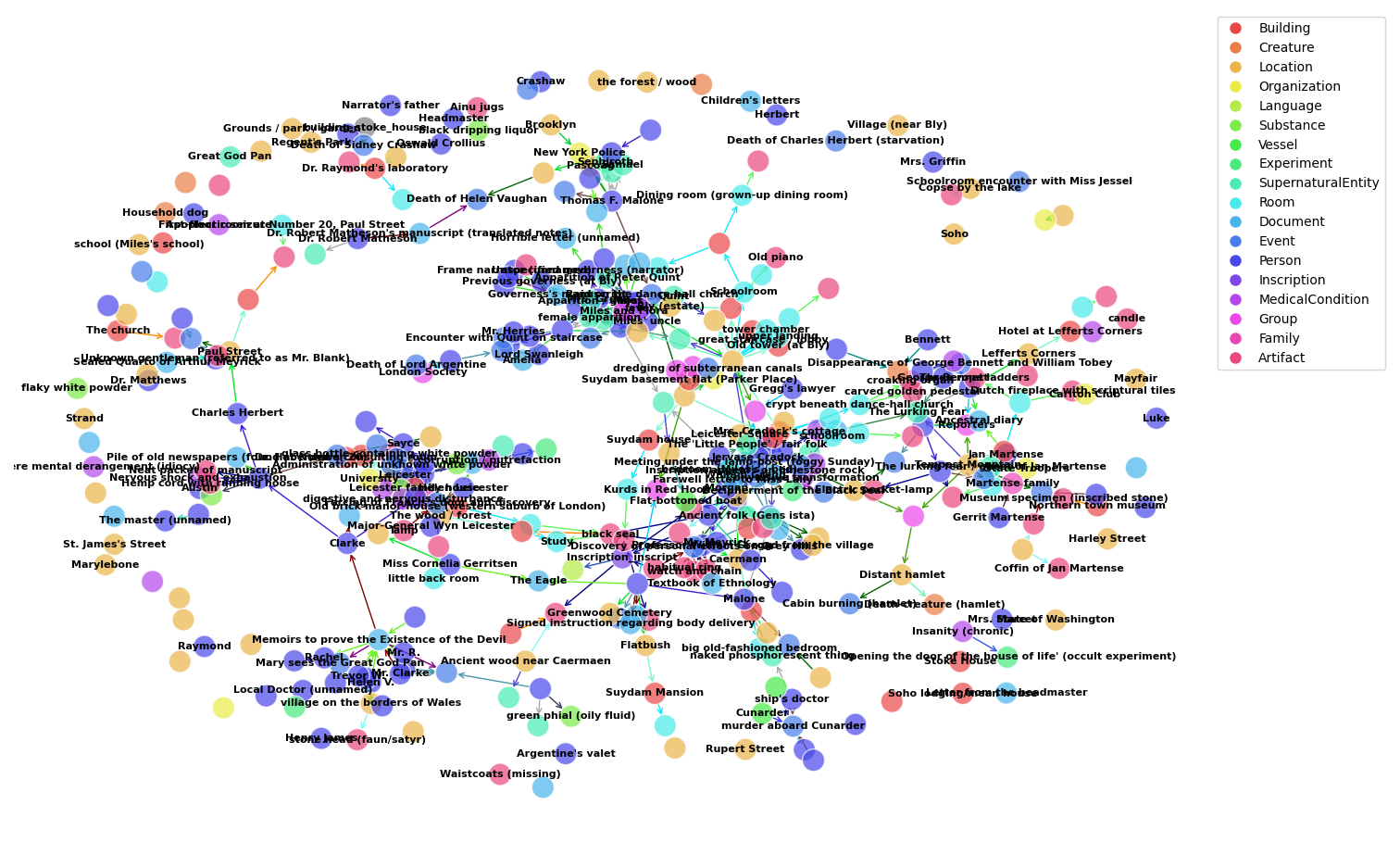
If you are curious, you can see the instances that form the basis for this knowledge graph here.
This visualization involves a little bit of massaging:
- Due to the quick implementation of instance extraction (via LLM), there were a number of duplicate instances. Each chunk of text sent to the model can potentially contain overlapping information with other chunks, so some characters, locations, and so on, are repeated across different instantiations.
- There are also a number of entity instances that have no relation instances. This is perfectly valid, but for the visualization these dangling nodes are downsampled.
Each color of edge and of node indicates a different type of object, corresponding to the elements of our ontology. Even at this level of fidelity, we are able to capture a good amount of the structure of the contents of these stories. With a little bit of polishing of the methodology to gather more structural information (regarding author and medium) and incorporation of more traditional techniques into the mix, we could pretty reliably generate knowledge graphs using a pipeline like this.
As foundation models eat more of the world, our ability to represent different kinds of information will only improve. Ontologies and knowledge graphs, with their abilities to structure data from a variety of different mediums, can help us order them.
Further Considerations
How well does this ontology extraction work with local models?
This quick workflow is run using GPT-5 entirely, with structured outputs. Local models have been showing some improvements here and there are a variety of cool tools for managing structured outputs, but that comes with the caveat of either paying for compute or slower performance.
How can we speed up realization of entity and relation instances?
In this workflow, we realize our entities using GPT-5 and structured outputs, and with a conventional API key there is a limit of 30,000 tokens per minute (TPM). The initial extraction of an ontology seems to work fairly well with this, but as the ontology defines the schema, we should expect the creation of instances from that schema to require orders of magnitude more time, compute, and tokens. This could be remedied by using conventional named-entity recognition (NER) tools to extract entities, then separately mapping them to the elements of our ontology. With enough data samples, we could train these models to make more direct predictions.
Could this be better served as an agent system?
Part of why this takes so long is that every piece of every text is handled separately, with some handling for API overloads in-between requests. We could instead do build some tooling that takes smaller chunks and filters them for information content, and incorporate some actual decision-making into how the text is analyzed and information is extracted. In the current state, this is a workflow, because we don’t have any variance in how the text should be analyzed, but there are likely ways to build tools for sampling and extraction that allow for the stochasticity necessary for agents to operate.